
Em uma recente série de vídeos do 3Blue1Brown, Grant Sanderson levantou uma questão intrigante: como um espaço de incorporação relativamente modesto de 12.288 dimensões (GPT-3) pode acomodar milhões de conceitos distintos do mundo real?
A resposta a esse enigma repousa na interseção da geometria de alta dimensão e um resultado matemático notável conhecido como lema de Johnson-Lindenstrauss. Durante a exploração dessa questão, descobri algo inesperado que levou a uma colaboração interessante com Grant e uma compreensão mais profunda da geometria do espaço vetorial.
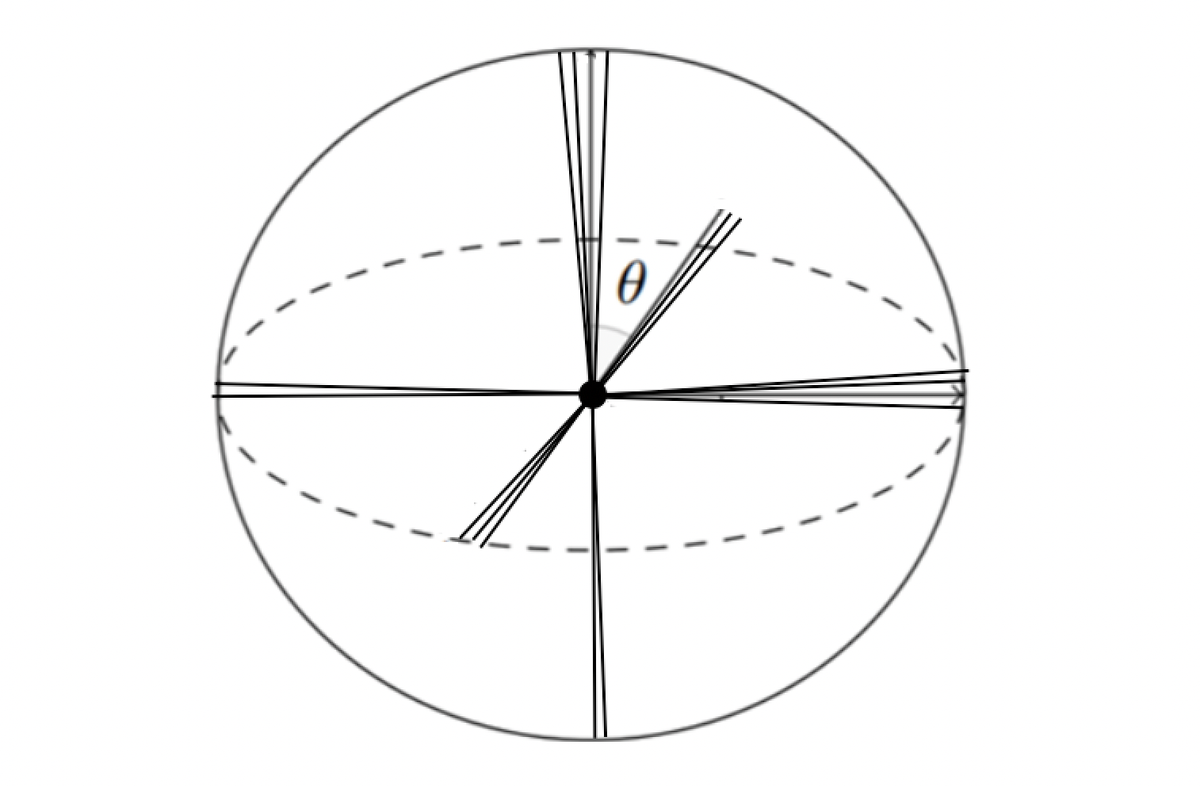
A chave para essa descoberta começa com uma observação simples: enquanto um espaço N-dimensional pode conter apenas N vetores perfeitamente ortogonais, relaxar essa restrição para permitir relações "quasi-ortogonais" (vetores a ângulos de, digamos, 85-95 graus) aumenta drasticamente a capacidade do espaço. Essa propriedade é crucial para entender como os modelos de linguagem podem codificar eficientemente o significado semântico em espaços de incorporação relativamente compactos.
No vídeo de Grant, ele demonstrou esse princípio com um experimento que tentava ajustar 10.000 vetores unitários em um espaço de 100 dimensões, mantendo relações quase ortogonais. A visualização sugeriu sucesso, mostrando ângulos agrupados entre 89 e 91 graus. No entanto, ao implementar o código eu mesmo, percebi algo interessante sobre o processo de otimização.
A função de perda original era elegantemente simples:
loss = (dot_products.abs()).relu().sum()
Embora essa função de perda pareça perfeita para um espaço ℝᴺ sem limites, ela encontra duas questões sutis, mas críticas, quando aplicada a vetores restritos a uma esfera unitária de alta dimensão. A primeira é a armadilha do gradiente, onde o produto escalar entre vetores é o cosseno do ângulo entre eles, e o gradiente é o seno desse ângulo. Isso cria uma estrutura de incentivo perversa: quando os vetores se aproximam da relação desejada de 90 graus, o gradiente (sin(90°) = 1.0) empurra fortemente em direção à melhoria. No entanto, quando os vetores se afastam do objetivo, o gradiente desaparece, efetivamente aprisionando esses vetores mal alinhados em suas configurações ruins.
A segunda questão é a "solução 99%", onde o otimizador encontrou uma solução estatisticamente favorável, mas geometricamente perversa. Para cada vetor, ele se tornava corretamente ortogonal a 9.900 dos 9.999 outros vetores enquanto era quase paralelo a apenas 99. Essa configuração, embora claramente não fosse o resultado pretendido, representava um mínimo global para a função de perda, semelhante a tomar 100 vetores base ortogonais e replicar cada um deles cerca de 100 vezes.
Diante disso, modifiquei a função de perda para usar uma penalização exponencial que aumenta agressivamente à medida que os produtos escalares crescem:
loss = exp(20*dot_products.abs()**2).sum()
Essa mudança produziu o comportamento desejado, mas com um resultado revelador: o ângulo máximo alcançável entre pares de vetores era cerca de 76,5 graus, e não 89 graus.
Essa descoberta me levou a um caminho fascinante, explorando os limites fundamentais do empacotamento de vetores em espaços de alta dimensão e como esses limites se relacionam com o lema de Johnson-Lindenstrauss. Quando compartilhei essas descobertas com Grant, sua resposta exemplificou o espírito colaborativo que torna a comunidade matemática tão gratificante. Ele não apenas apreciou a correção técnica, mas me convidou a compartilhar essas percepções com o público do 3Blue1Brown. Este artigo é essa resposta, ampliada para explorar as implicações mais amplas dessas propriedades geométricas para aprendizado de máquina e redução de dimensionalidade.
O lema de Johnson-Lindenstrauss faz uma promessa notável: é possível projetar pontos de um espaço de alta dimensão para um espaço de dimensão surpreendentemente baixa, preservando suas distâncias relativas com alta probabilidade. O que torna esse resultado particularmente impressionante é que a dimensionalidade necessária do espaço de baixa dimensão cresce apenas logaritmicamente com o número de pontos que você deseja projetar. O lema afirma que para um fator de erro ε (entre 0 e 1) e qualquer conjunto de N pontos em um espaço de alta dimensão, existe uma projeção em k dimensões onde para qualquer dois pontos u e v no espaço original, suas projeções f(u) e f(v) no espaço de menor dimensão satisfazem:
(1 - ε)||u - v||² ≤ ||f(u) - f(v)||² ≤ (1 + ε)||u - v||²
O número de dimensões (k) necessárias para garantir esses limites de erro é dado por:
k ≥ O(log(N)/ε²)
Enquanto a maioria dos profissionais utiliza valores entre 4 e 8 como uma escolha conservadora para projeções aleatórias, o valor ótimo de C permanece uma questão em aberto. Como veremos na seção experimental, projeções engenheiradas podem alcançar valores de C muito mais baixos, com profundas implicações para a capacidade do espaço de incorporação.
A história fascinante desse resultado fala da natureza interconectada da descoberta matemática. Johnson e Lindenstrauss não estavam realmente tentando resolver um problema de redução de dimensionalidade; eles se depararam com essa propriedade enquanto trabalhavam na extensão de funções Lipschitz em espaços de Banach. O artigo de 1984 deles revelou-se muito mais influente na ciência da computação do que em seu domínio original.
O lema de JL encontra aplicação prática em duas áreas distintas, mas igualmente importantes: redução de dimensionalidade e capacidade de espaço de incorporação. Quando consideramos um cenário prático, como uma plataforma de comércio eletrônico, onde as preferências de cada cliente podem ser representadas por um vetor com milhões de dimensões, a JL nos diz que podemos projetar esses dados em um espaço de dimensão muito menor, talvez apenas mil dimensões, preservando as relações essenciais entre os clientes. Isso torna cálculos antes intratáveis viáveis em uma única GPU, permitindo gestão de relacionamento com clientes e planejamento de inventário em tempo real.
Por outro lado, a aplicação de capacidade de espaço de incorporação é mais sutil, mas igualmente poderosa. Em vez de projetar ativamente vetores, estamos interessados em entender quantos conceitos distintos podem coexistir naturalmente em um espaço de dimensão fixa. Essa pesquisa oferece insights valiosos sobre os limites práticos da capacidade do espaço de incorporação, considerando que os modelos de linguagem não lidam com relações perfeitamente ortogonais — conceitos do mundo real exibem graus variados de semelhança e diferença.
Quando passamos de projeções aleatórias para soluções engenheiradas, os limites teóricos para C do lema de JL tornam-se surpreendentemente conservadores. Experimentos em GPU sugerem que arranjos ainda mais eficientes são possíveis através da otimização. Realizei uma série de experimentos projetando vetores padrão em espaços de diversas dimensões. Os resultados revelam padrões fascinantes, como um aumento nos valores de C com N, alcançando um máximo em torno de ~0,9, e depois uma tendência consistente de queda. Essa observação sugere que, conforme a dimensionalidade aumenta, o empacotamento de esferas se torna mais eficiente quando as esferas são pequenas em relação à esfera unitária.
As implicações dessas propriedades geométricas são extraordinárias. Ao considerar três cenários para a constante C, percebemos que a escolha conservadora de C = 4 para projeções aleatórias, C = 1 como um limite superior provável para embeddings otimizados, e C = 0,2 sugerido por nossos experimentos para espaços muito grandes, trazem à tona a capacidade dos espaços de incorporação em manter relações ricas e nuançadas entre milhões de conceitos.
Em conclusão, essa investigação sobre um problema de otimização sutil nos levou a uma apreciação mais profunda da geometria de alta dimensão e seu papel no aprendizado de máquina moderno. O lema de Johnson-Lindenstrauss, descoberto em um contexto diferente quase quatro décadas atrás, continua a fornecer insights sobre as fundações de como podemos representar significados em espaços matemáticos. Agradeço sinceramente a Grant Sanderson e ao canal 3Blue1Brown. Seu trabalho inspira consistentemente uma exploração mais profunda de conceitos matemáticos, e sua abertura à colaboração exemplifica os melhores aspectos da comunidade matemática.



Confira os últimos vídeos publicados no canal

A maior virada da Inteligência Artificial começou... e vem da China

o ALERTA de Satya Nadella que ASSUSTOU o mercado de IA

GPT 5.6 SURPREENDE: OpenAI finalmente alcançou a Anthropic?

Os novos modelos de IA estão decepcionando... e ninguém quer admitir isso

Midjourney quer ESCANEAR humanos e o Open Source já rivaliza com Claude Opus

Rio 3.5 e Fable 5: as duas polêmicas que expõem o futuro da IA

Fim dos PCs como conhecemos: Nvidia, Microsoft e IA local vão mudar tudo

O plano SECRETO das Big Techs para cobrar MUITO mais pela IA

BOLHA da IA ou NOVA era de crescimento EXPONENCIAL? O mercado está dividido

Nova IA da OpenAI traduz em TEMPO REAL e pode mudar o mundo dos negócios

Spec Driven Development (SDD): a habilidade que vai separar quem SOBREVIVE à IA

DeepSeek V4: o Open Source que está AMEAÇANDO GPT 5.5 e Opus 4.7

Prometeram Renda Universal… mas só veio desemprego?

Mythos Preview: o começo da AGI ou só mais hype?

Ele automatizou TUDO com IA… e pode virar bilionário sozinho


